In numerical linear algebra, the Jacobi method is an algorithm for determining the solutions of a system of linear equations with largest absolute values in each row and column dominated by the diagonal element. Each diagonal element is solved for, and an approximate value plugged in. The process is then iterated until it converges. This algorithm is a stripped-down version of the Jacobi transformation method of matrix diagonalization. The method is named after German mathematician Carl Gustav Jakob Jacobi.
Given a square system of n linear equations:
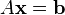
where:
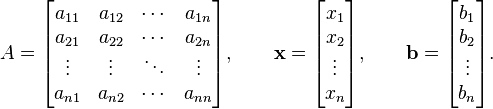
Then A can be decomposed into a diagonal component D, and the remainder R:

The system of linear equations may be rewritten as:

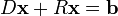
and finally:
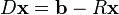
The Jacobi method is an iterative technique that solves the left hand side of this expression for x, using previous value for x on the right hand side. Analytically, this may be written as:

The element-based formula is thus:

Note that the computation of xi(k+1) requires each element in x(k) except itself. Unlike the Gauss–Seidel method, we can't overwrite xi(k) with xi(k+1), as that value will be needed by the rest of the computation. This is the most meaningful difference between the Jacobi and Gauss–Seidel methods, and is the reason why the former can be implemented as a parallel algorithm, unlike the latter. The minimum amount of storage is two vectors of size n.
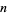 equations of the
equations of the 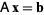 one at a time in sequence, and uses previously computed results as soon as they are available,
one at a time in sequence, and uses previously computed results as soon as they are available, 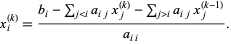
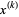 depends upon the order in which the equations are examined. If this ordering is changed, the components of the new iterates (and not just their order) will also change.
depends upon the order in which the equations are examined. If this ordering is changed, the components of the new iterates (and not just their order) will also change. 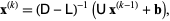
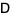 ,
, 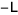 , and
, and 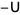 represent the
represent the 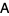 , respectively.
, respectively.  .
. 
